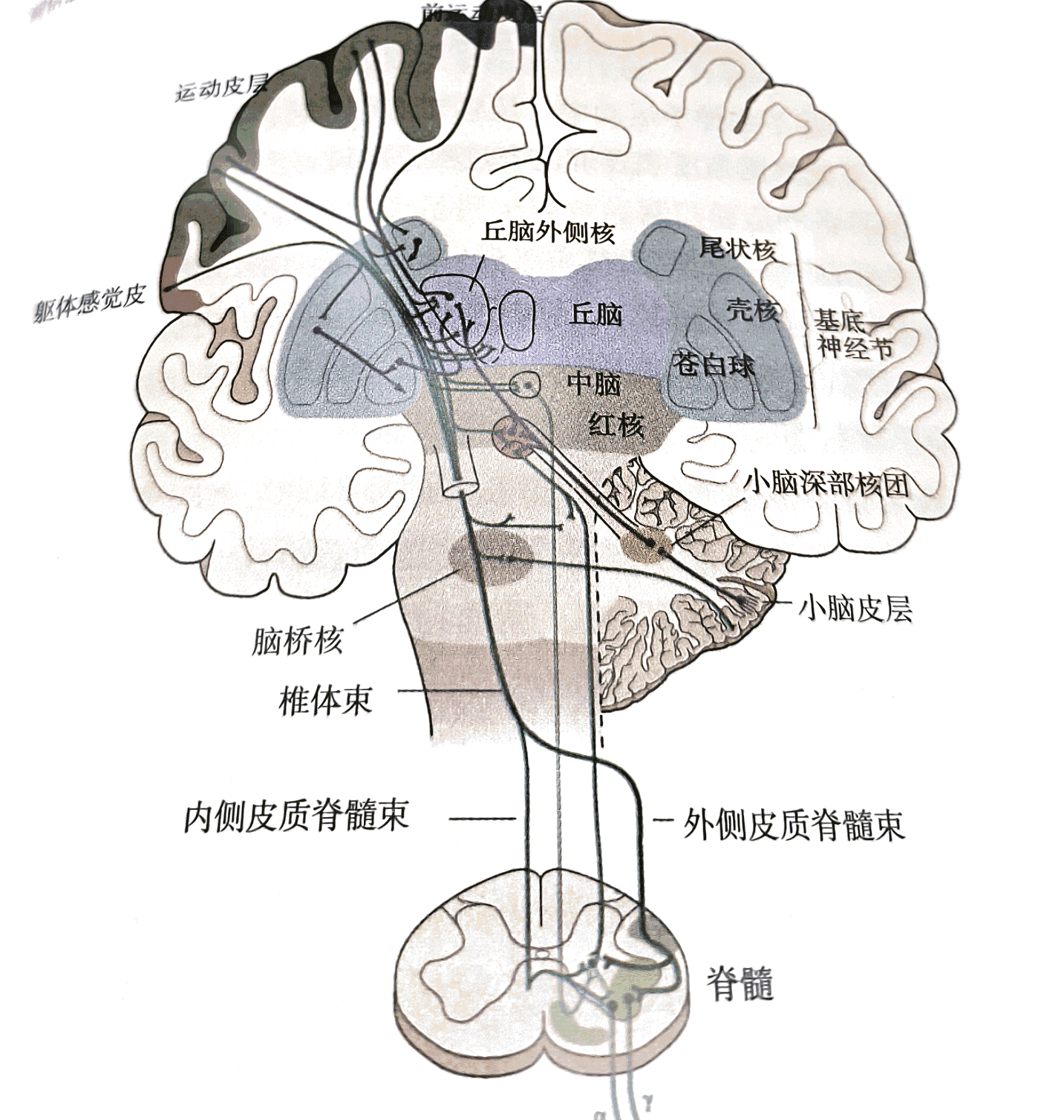
如果大脑地图是一件“画作”,其美妙之处在于,她无时无刻不在动态变化,同时,有些预设却没有变化—— David 9
上一次,我们已经提到了参考帧,参考帧在新皮层中无处不在,我们的触觉可以引导视觉的预测,视觉反过来又可以引导触觉的预测(就像你在黑盒子中摸奖品)。并且不要忘了,我们身体的的各个部分能够很好地协调,也是参考帧的传递在起作用。
参考帧的巧妙联合,组成了所谓“大脑地图”的特征(或失真)。Rebecca Schwarzlose的《大脑地图》进行了更详细的探讨。大脑无时无刻发送参考帧的神经元就像俯瞰广场上的群众,每个人都有自己的声音,每个人之间又可以相互交流:
这种分布式信息传递在局部甚至全局又可以形成统一的共识,这种共识我们可以笼统地叫做“大脑地图”,显然地图反映了大脑系统对外部世界的认识,需要强调的是,这种认识在很多情况下都是失真的,如下左图是猕猴观看的图案,右图是脑区V1的对应活动:
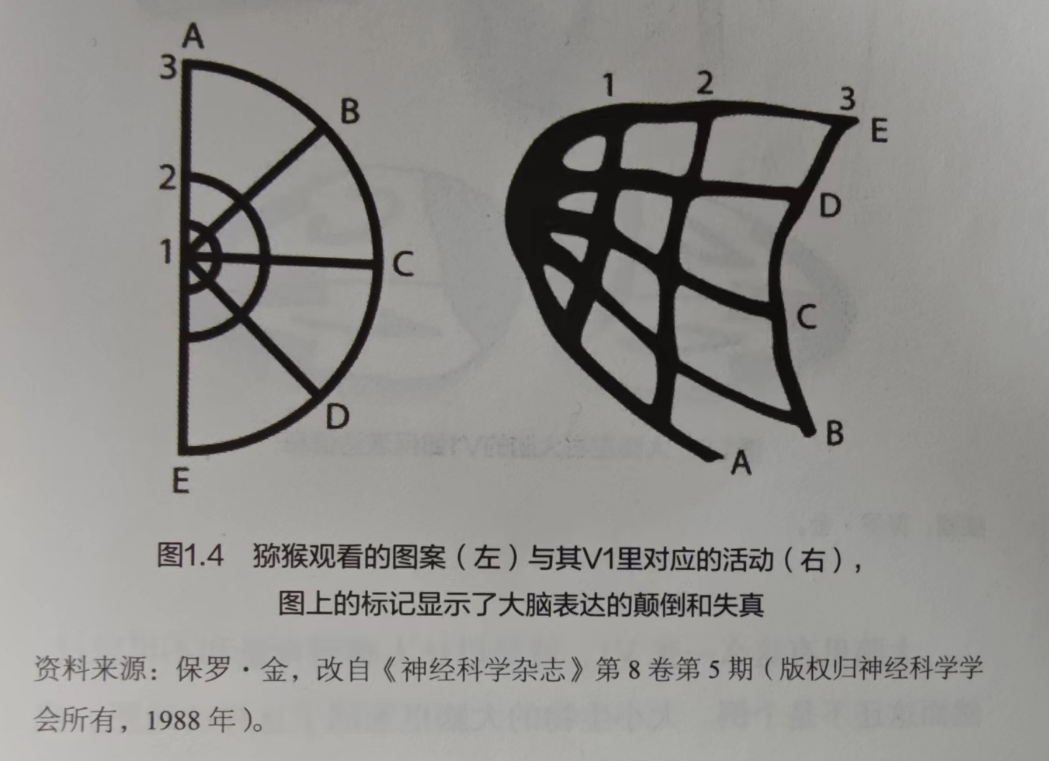
但是,“失真”不代表是失效的,恰恰相反,失真对物种的生存起到至关重要的作用,我们需要派遣更多的神经细胞去处理更值得关注的对象和区域(无论是视觉域还是声域),不是吗?
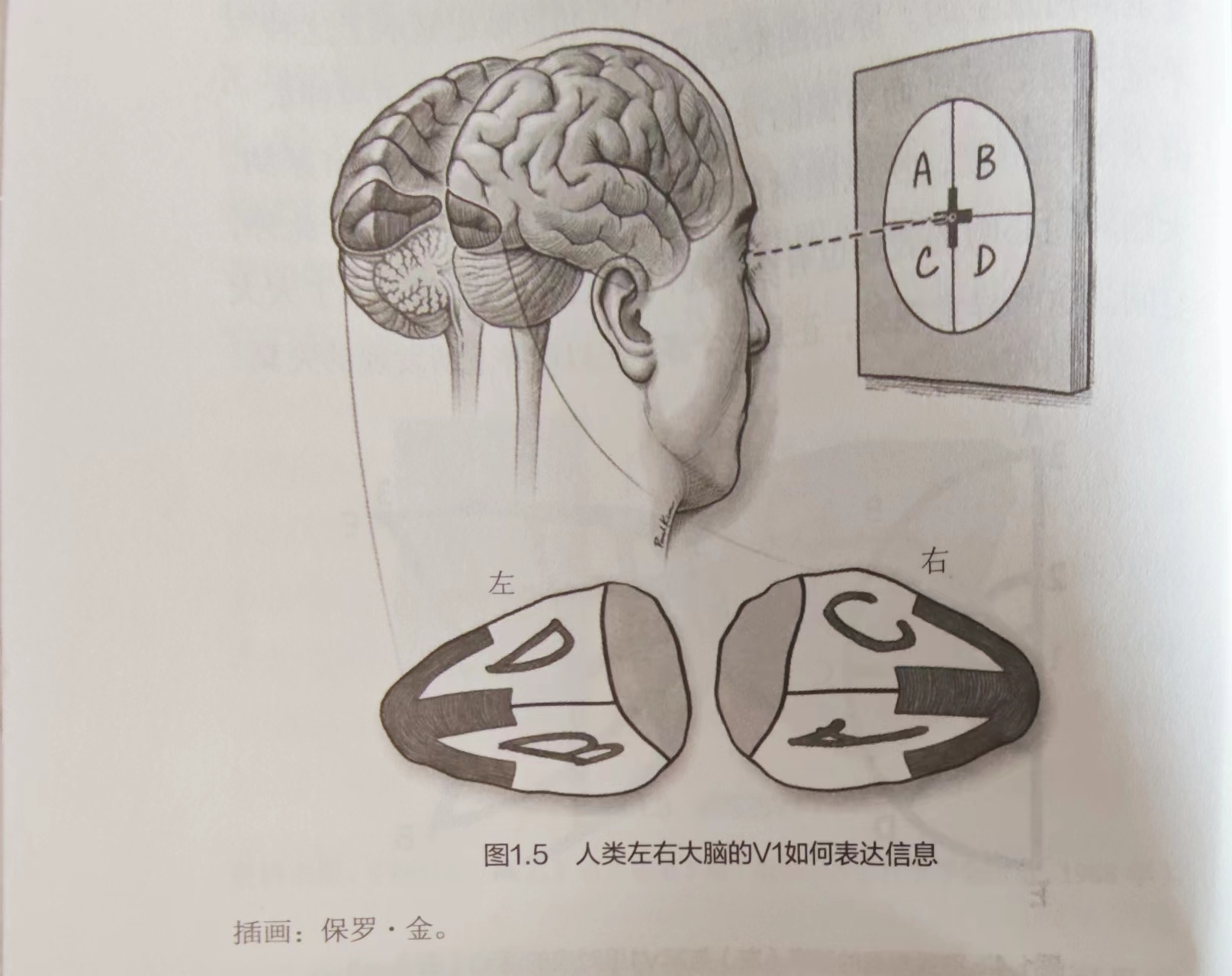
因此,在人脑V1区也会有失真的表达存在:
 事实上,人类的大脑地图有更丰富的失真表达,如果以奥古斯特的《犹豫不决的未婚妻》为例(下图),我们首先会去多数把注意力集中到屏幕中间的新娘及其表情,甚至与之心理产生一定的共情,这时,新娘以外的画面对我们来说几乎是不存在的,之后慢慢地,我们才会把注意力拉回到整个画面极其各个对象的活动中来,并且会调动除了视觉以外的感官去感受整个场景:
事实上,人类的大脑地图有更丰富的失真表达,如果以奥古斯特的《犹豫不决的未婚妻》为例(下图),我们首先会去多数把注意力集中到屏幕中间的新娘及其表情,甚至与之心理产生一定的共情,这时,新娘以外的画面对我们来说几乎是不存在的,之后慢慢地,我们才会把注意力拉回到整个画面极其各个对象的活动中来,并且会调动除了视觉以外的感官去感受整个场景: