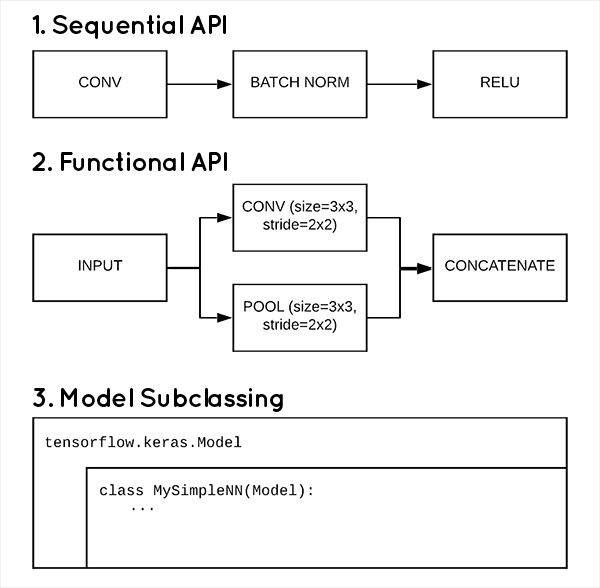
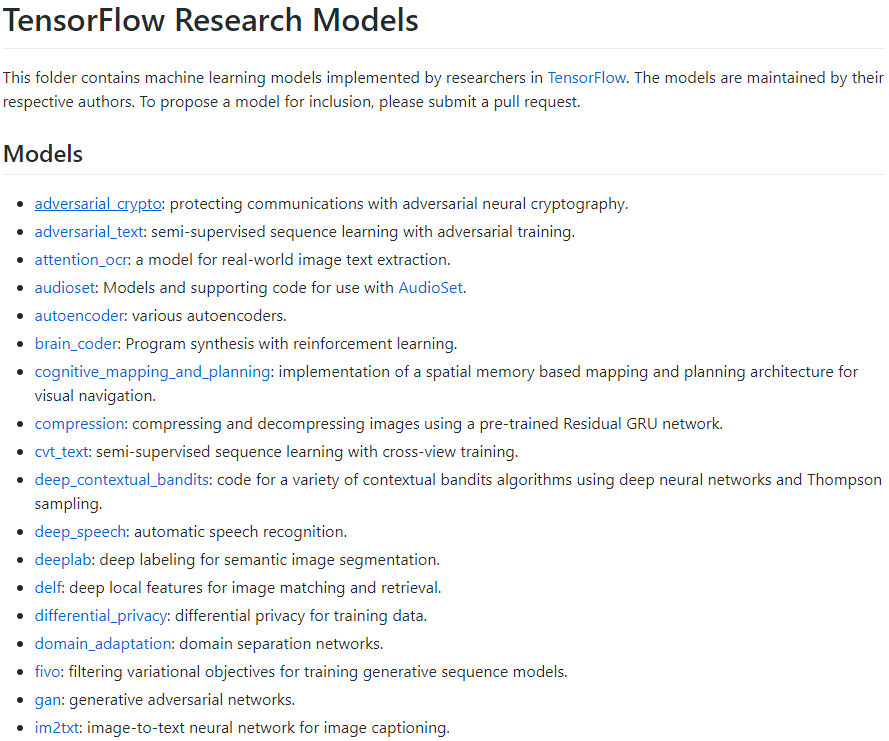
TensorFlow Models项目是谷歌TensorFlow项目下存放大量官方SOTA模型和论文模型实现的子项目,大量的科研学习可以从这里开始(每个论题模型都是科研机构各自维护的):
 但要快速上手任意模型,对于普通科研人员并不容易(除非你同时是CS系或同时熟悉C和python编程等)。这里David就带大家绕过一些不必要的坑。
但要快速上手任意模型,对于普通科研人员并不容易(除非你同时是CS系或同时熟悉C和python编程等)。这里David就带大家绕过一些不必要的坑。
拿models/research下的迁移学习domain_adaptation项目为例(NIPS 2016论文),缺少编程经验的朋友(或者只会python的朋友)如果按照introduction走,很快就傻眼了:
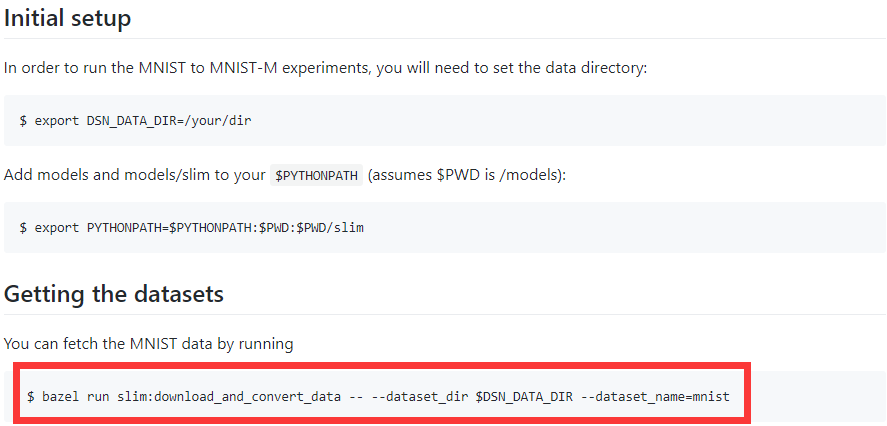
普通科研人员不会知道bazel是google的一个编译工具,也不知道slim是什么东西(TF-slim其实是TensorFlow Models项目中独立出来的通用库)。事实上,对于只需研究模型本身的研究人员,这些都可以绕过!对于上述红框中的命令你完全可以用下面命令替代:
# python download_and_convert_data.py -- --dataset_dir $DSN_DATA_DIR --dataset_name=mnist
Models子项目虽然用bazel管理,但本质上都是TF的python项目,你总能找到python主入口跑这个项目,而不是用bazel这种专业工具(谷歌内部喜欢用的工具)。同样,slim本质上也是一个python库,用python脚本跑程序就可以:
$ python download_and_convert_data.py \
--dataset_name=flowers \
--dataset_dir="${DATA_DIR}"
另外,路径出错也是常见错误,
Traceback (most recent call last):
File "dsn_eval.py", line 28, in <module>
from domain_adaptation.datasets import dataset_factory
ImportError: No module named domain_adaptation.datasets
如上错误很可能是domain_adaption这个文件夹路径没有找到而已,这时对于一些不熟悉linux命令行的朋友,建软链或加环境变量不是最佳选择,最直接的方法是修改代码,比如在代码中插入下面两行,就可以把目录上两级库也添加进来,解决问题: 继续阅读给普通科研人员跑TensorFlow Models项目的一点建议,编译tf,谷歌Bazel,TensorFlow Slim和其他