我不害怕所谓的“AI统治人类”,我更害怕在未来拥有自由感情的AI被人类奴役 — David 9
如果你在深夜一个人静静地思考,一定问过自己那三个终极问题(我是谁?我在哪?我要到哪去?)。还有,“上帝存在吗?”,很显然这个命题的争论一直没有科学一致的解答。但要研究“智能”的本质(或强AI),我们有必要探索这些问题。
事实上,在神学和认知论领域,“上帝是否存在?”这种较难问题往往不能直接论证,争辩的战场更多的是像“我们信仰上帝是理智的吗?”,“我们的思想是自主的吗?”这类问题:
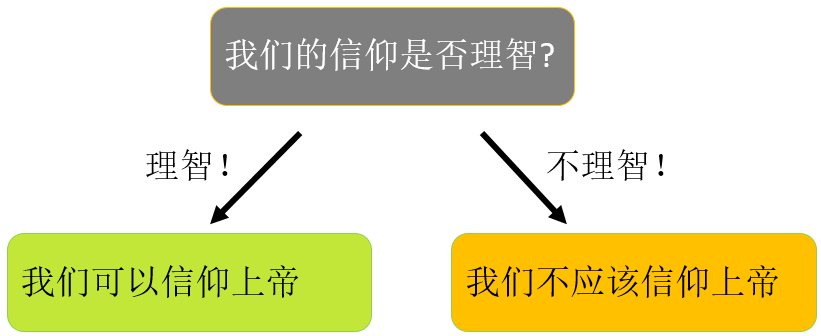 有神论者一定会竭力辩护“人类产生对上帝的信仰是恰当理智的”这种命题,而无神论者则相反。我们从正方开始。
有神论者一定会竭力辩护“人类产生对上帝的信仰是恰当理智的”这种命题,而无神论者则相反。我们从正方开始。
借用大名鼎鼎的基督哲学家阿尔文• 普兰丁格的改良认识论(Reformed Epistemology)的脉络,我们先思考一个简单的问题:
对于类似“上帝看着我。”,“这次上帝会原谅我的。”
这些想法,是否和:
“我生活的这个世界应该已经存在很多年了。”,“那个人好像很生气。”,“他(她)这时可能在想我”这些想法非常相似?
这些命题都无法直接论证(或基于其他“知识”),但都似乎有人暗示过我们,更重要的是:我们好像是无人逼迫的情况下,通过理智去相信(或者不相信的)。
也好像,这种“灵性”是与生俱来在那里,别人不是“暗示”,只是帮我们“确认”而已。
那么你愿意相信这种“灵性”(或“感知”)是无神论者口中的“非理性”吗?
更有意思的问题是:这种比目前的卷积CNN(RNN)高级很多的感知和信仰,是如何产生的?
首先,这些信仰很难基于其他确切知识去推断。我们的知识体系大致如下:
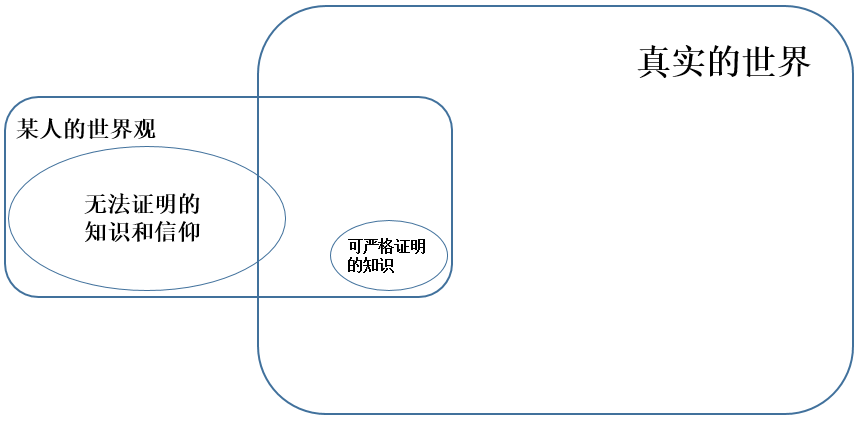
为什么我把“无法证明的知识和信仰” 画的辣么大?事实上,就是这么大!对于普通人,严格正确的知识根本不重要,哪怕没有一点确凿知识(只需要一些日常逻辑)也可以正常适应生活。 继续阅读“即使无法证明上帝存在,人类的信仰也合乎理智”:”信仰”和”智能”的哲学启发,David_9的神学与认识论随笔