
用神经网络去替代人为塑造的损失函数(成本函数), 似乎已成一种趋势 — David 9
NIPS:神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际顶级会议。该会议固定在每年的12月举行,由NIPS基金会主办。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议。

截止2016年底,NIPS大会已经办了29个年头,关于会议流程与相关细节,可以参考这篇文章。
今天的论文精选是来自UC Berkeley的论文: Value Iteration Networks (价值迭代网络) . 很厉害地被评为今年的NIPS 2016最佳论文. 毫无疑问是和深度学习和增强学习的结合(近年来的重头戏) .
文章最大的贡献跟随现阶段深度学习的一种趋势: 用神经网络去替代人为塑造的损失函数(成本函数). 更好地计划, 预测未知的域. 这样做的优势在我们之前讲过的生成对抗网络101中提到过:
正如”对抗样本与生成式对抗网络“一文所说的: 传统神经网络需要一个人类科学家精心打造的损失函数。但是,对于生成模型这样复杂的过程来说,构建一个好的损失函数绝非易事。这就是对抗网络的闪光之处。对抗网络可以学习自己的损失函数——自己那套复杂的对错规则——无须精心设计和建构一个损失函数.
而这篇文章最核心的损失函数, 正是增强学习中用于策略评估的回报函数/价值函数. 最有意思的贡献, 就是不再用传统的指数家族函数或者log损失函数去模拟价值函数, 而是在框架中加入一个VI(Value iteration)模块, 让CNN神经网络去学习价值函数吧:
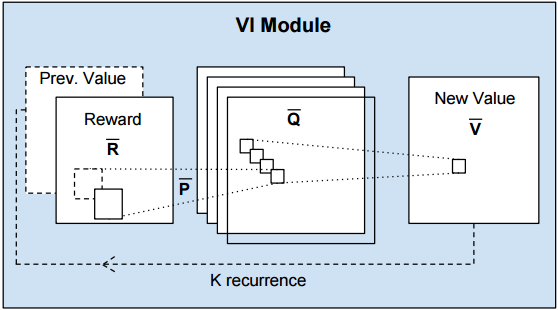
是不是有点意思 ? 但是在精读文章前, 我们必须先搞清两个问题:
- 什么是增强学习中的价值迭代? 传统的增强学习价值迭代过程, 与本文使用CNN的价值迭代的差别 ?
- 上述的VI模块, 是如何结合到整个增强学习框架中 ? 又是如何解决实际问题的 ?
首先, 传统增强学习的价值迭代, 是在每次迭代根据已有的一些行为, 状态转移, 以及回报的信息, 更新价值函数:
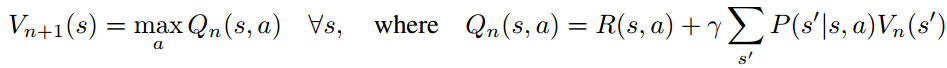 实际是一个马尔可夫决策过程(MDP). MDP的重要元素有:
实际是一个马尔可夫决策过程(MDP). MDP的重要元素有:
表示状态转移的一些状态: ![]()
一些行为(actions): ![]()
回报函数![]() 由当前状态和行为决定.
由当前状态和行为决定.
转移概率![]() 当前状态和行为导致转移到另一个状态的概率.
当前状态和行为导致转移到另一个状态的概率.
所以, MDP的目标是: 一系列的状态-行为序列: ![]() , 我们要找到一个策略π, 使得总的状态轨迹价值最大 :
, 我们要找到一个策略π, 使得总的状态轨迹价值最大 :
![]()
其中![]()
而且, 这里的价值函数V不是学习而来的, 是科学家们精心打造出来的. 这就解释了文章开头的想法: 在框架中加入一个VI(Value iteration)模块, 让CNN神经网络去学习价值函数吧:
而这个VI模块可以看作CNN神经网络
输入是: 回报R, 转移概率P和上次迭代的价值函数Pre V,
输出是: 价值函数V. 之所以看做CNN, 是针对一些回报R是局部相关的问题.
其次, VI模块是这样放到整个增强学习框架的:
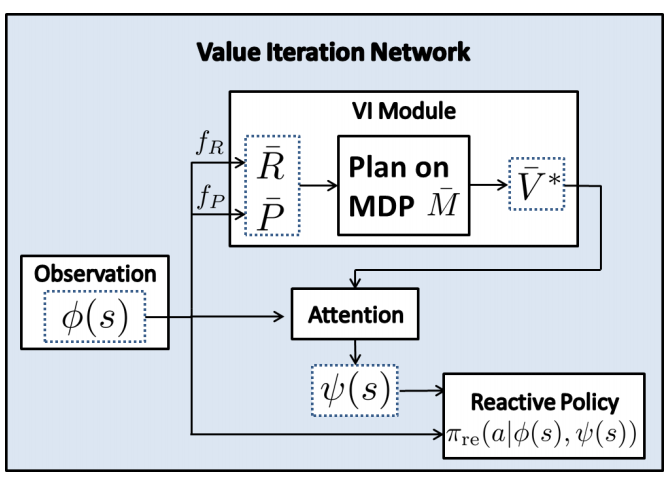
这里的ψ(s) 和 Φ(s) 是对状态s的观察, 对于走格子迷宫这样的问题, 我们可以过滤一下ψ(s)(Attention模块), 因为每走一部, 下一步状态只有少数几个的状态可能性:
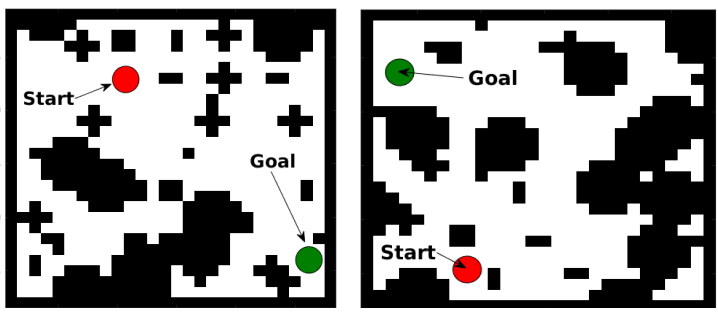
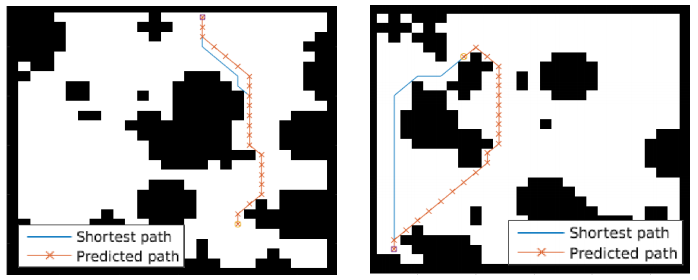
另外看一下作者的实验结果:
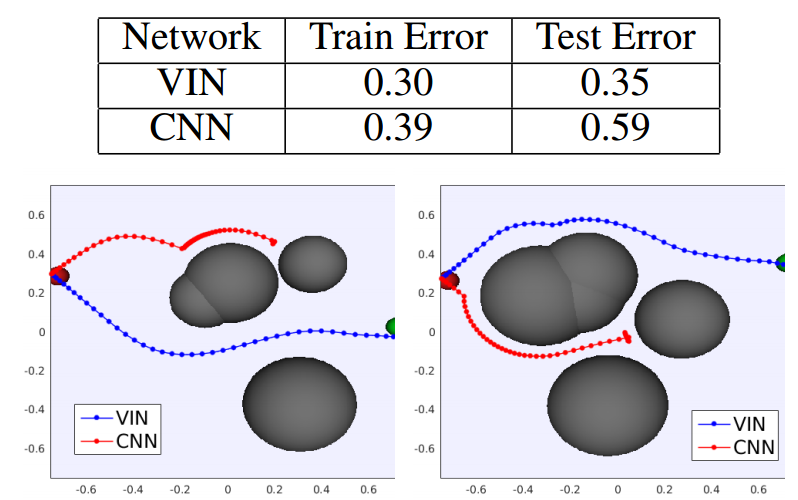
这是粒子轨迹控制的模拟实验.
之所以VIN(价值迭代网络) 比普通的深度增强学习(与CNN结合) 效果好, 是因为VIN是用神经网络表示和学习价值函数(我们假设价值函数是未知的),
而CNN强化学习仅仅表示和学习的是策略函数:![]()
没有假设价值函数是未知的, 而是人工打造的.
参考文献:
- https://en.wikipedia.org/wiki/Conference_on_Neural_Information_Processing_Systems
- https://nips.cc/Conferences/2016/Schedule?type=Poster
- NIPS 2016 Spotlight Videos
- 增强学习Reinforcement Learning经典算法梳理1:policy and value iteration
- 机器学习顶级会议NIPS 2015
- http://artint.info/html/ArtInt_227.html
- VIN 的 TensorFlow 实现
- 原作者的 Theano 实现
- 维基百科: 马尔可夫决策过程
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024