
机器自主编程的发展比我们想象的要快, 并且, 人们容易忽略的是, 互联网上数不尽的源代码本身是高质量的”训练数据”. —— David 9
今天的最佳论文, 是伯克利改进去年 DeepMind 突破性论文: NPI (神经编程解释器). 论文题为: MAKING NEURAL PROGRAMMING ARCHITECTURES GENERALIZE VIA RECURSION
能够让机器自己具有推理能力和编程能力一直是人们梦想, 而如今, 即使深度学习和神经网络发展壮大, 我们在这一领域依然是”婴儿学步”. 去年DeepMind的论文NEURAL PROGRAMMER-INTERPRETERS (NPI) 又似乎让我们看到了曙光. 一旦研究能在工业界大范围应用, 使用伪代码编程, 甚至构造”自治”的下一代互联网都成为可能.
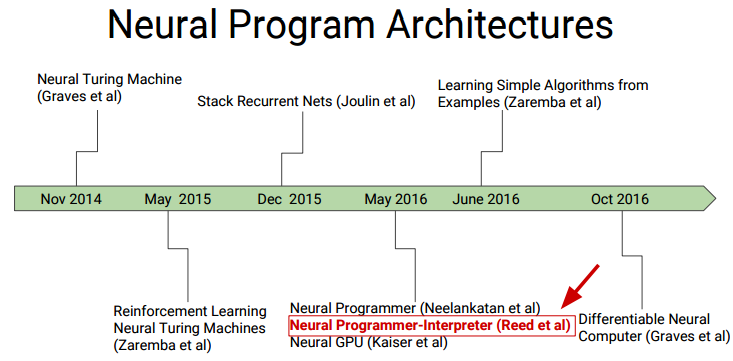
言归正传, 伯克利的这篇论文对去年NPI的改进, 已经能够模拟简单的冒泡排序,拓扑排序,快速排序, 小学生进位加法运算等简单算法. 基本目标如下:
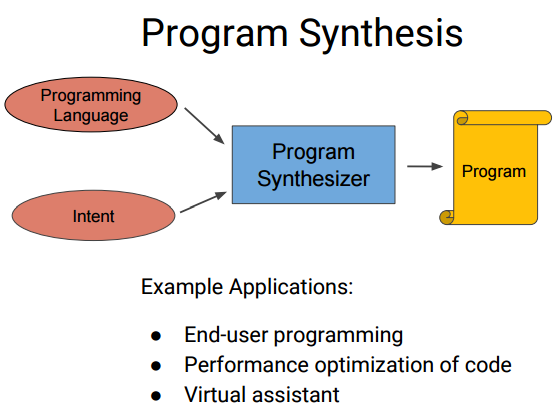
上图蓝色部分是NPI核心, 目标是训练出一个神经网络(往往基础是LSTM), 来模拟一个程序的行为. 最后训练出一个和目标程序行为一样的神经网络.
读者可能好奇训练数据是什么? 事实上, 你可以想象你对程序写白盒测试时有许多程序流的跳转和环境变量等等, 这些测试用例, 就是训练数据. 给一些更直观点的例子:
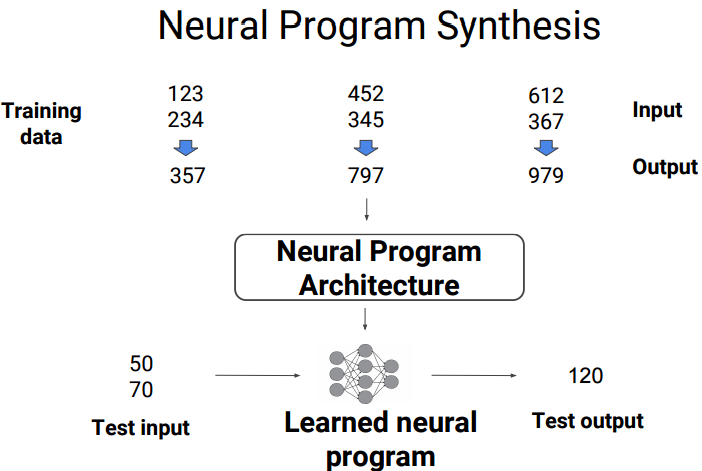 )
)小学生进位加法大家一定做过, 可以想象, 用神经网络训练后, 可以得到网络, 好像学会了进位加法一样, 把最终的结果输出给你.
当然前提是, 你给神经网络足够的训练用例, 或者告诉它进位加法的内在逻辑是什么. 正如小时候老师把关键点教给我们: 每一位的加法都是一样的, 如果超过10不要忘记进位到下一位, 以此类推即可.
而这篇论文告诉我们 , 训练用例如果尽量多地使用递归, 可以提高神经网络泛化能力. 并且文章对这种方法的有效性进行了证明.
理解改进算法前, 我们先要理解NPI的工作原理:
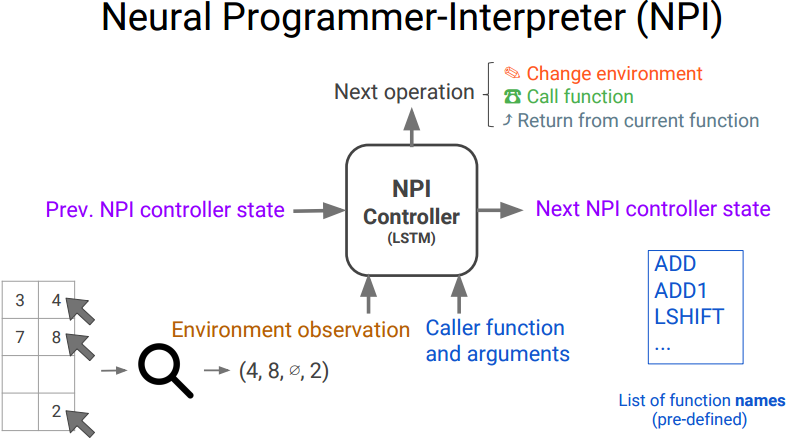
NPI控制器的输入有程序运行的环境, 上一次的NPI状态, 本次调用函数及其参数, 等等. 输出是下一个状态及程序的运行环境, 下个应该别调用的函数, 等等.
上图右下角的指令即每一步应该调用的函数列表. 下面是小学进位加法的程序实例(包括不使用递归和使用递归的情况):
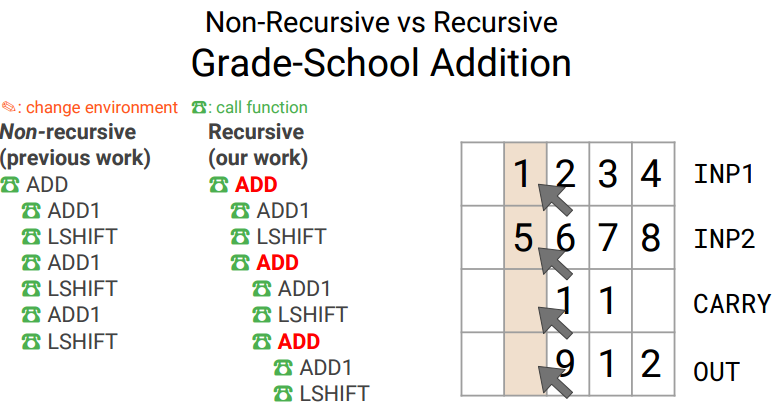
左边是没有递归的指令串, 右边是使用递归的指令串, 实现的功能是一样的, 即进位加法. 但是, 右边使用递归的方式, 可以让神经网络学习到一些重点的内容: 经常在递归中出现的重复行为. 从而在RNN中提高泛化能力. 可见, 研究员为了让机器学到一些关键点, 真是操碎了心.
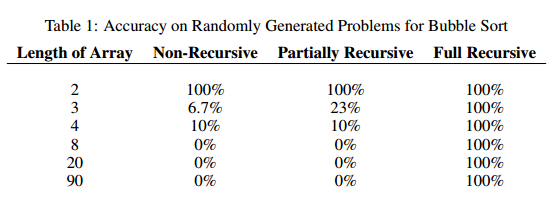
下面是使用递归训练NPI 与传统NPI对比:

参考文献:
- MAKING NEURAL PROGRAMMING ARCHITECTURES GENERALIZE VIA RECURSION
- http://www.iclr.cc/lib/exe/fetch.php?media=iclr2017:cai_iclr2017.pdf
- https://36kr.com/p/5062703.html
- http://zcyoung.cn:8080/news/44222
- https://www.youtube.com/watch?v=B70tT4WMyJk
- NEURAL PROGRAMMER-INTERPRETERS
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:)yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024