所谓无监督学习,只是人类加入了约束和先验逻辑的无监督 — David 9
更新:有同学发现这篇文章可能并没有在CVPR2018最终录取名单(只是投稿),最终录取名单参考可以看下面链接:
https://github.com/amusi/daily-paper-computer-vision/blob/master/2018/cvpr2018-paper-list.csv
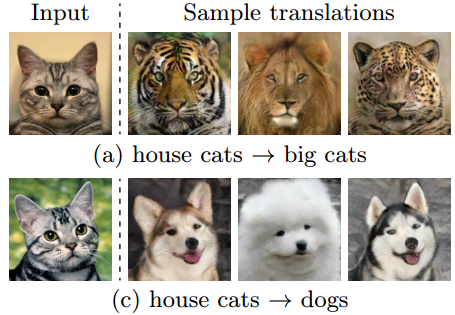
最近图片生成领域正刮着一股“无监督”之风,David 9今天讲Cornell大学与英伟达的新作,正是使无监督可以生成“多态”图片的技术,论文名:Multimodal Unsupervised Image-to-Image Translation (MUNIT)。
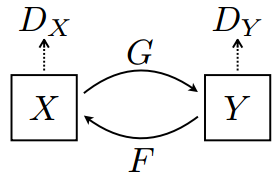
这股“无监督”之风的刮起,只是因为我们发现用GAN结合一些人为约束和先验逻辑,训练时无需监督图片配对,直接在domain1和domain2中随机抽一些图片训练,即可得到样式转换模型。这些约束和先验有许多做法,可以迫使样式转换模型(从domain1到domain2)保留domain1的一些语义特征;也可以像CycleGAN的循环一致约束,如果一张图片x从domain1转换到domain2变为y,那么把y再从domain2转换回domain1变为x2时,x应该和x2非常相似和一致:
而这些无监督方法有一个缺陷:不能生成多样(多态)的图片。MUNIT正是为了解决这一问题提出的,因为目前类似BicycleGAN的多态图片生成方法都需要配对监督学习。
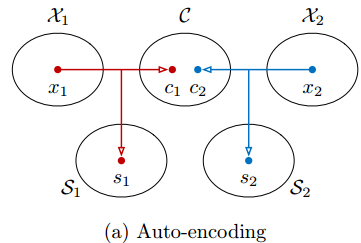
MUNIT为此做了一些约束和假设,如,假设图片有两部分信息:内容c和样式s,另外,图片样式转换时domain1和domain2是共享内容c的信息空间的:
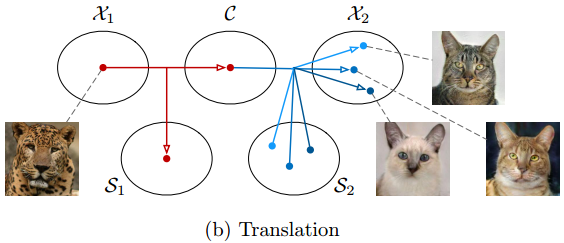
生成图片时,把同一个内容c和不同样式s组合并编码输出,就可生成多态的图片:
实际训练时,我们需要两个自编码器,分别对应domain1和domain2:
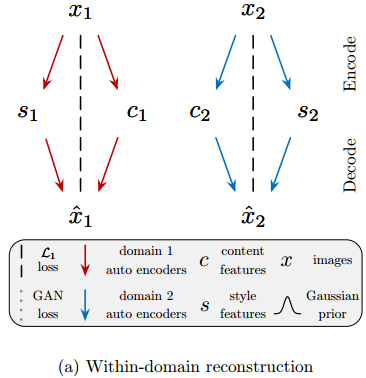
两个自编码器都要先在各自的domain中训练,过程中需要保证同一张图片x1可以被还原出相似的域中图片 ,即所谓的让x1的domain内部重构的loss降到最小:
,即所谓的让x1的domain内部重构的loss降到最小:
![]() 其中E1是x1的编码器(分别编码成内容信息c和样式信息s),G1是解码器(根据c和s)解码成domain1中图片。
其中E1是x1的编码器(分别编码成内容信息c和样式信息s),G1是解码器(根据c和s)解码成domain1中图片。
生成样式转换图片时,把另一个domain中的内容信息c2拿过来与当前domain的样式信息s1拼接,再解码生成新的图片,就可以从domain2生成domain1样式的图片x2->1,下图即交叉domain的转换方法:
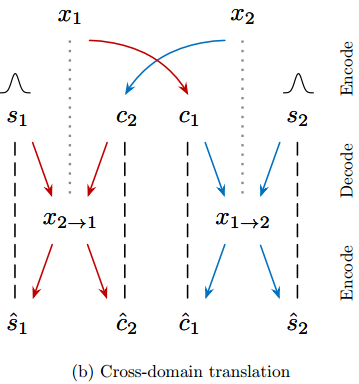
这时对于转换后的图片x2->1, 需要构建所谓的隐含特征重构loss(latent reconstruction loss),即,用编码器再对图片x2->1编码后,依然可以得到内容信息c2与样式信息s1(显然这时符合直觉的):
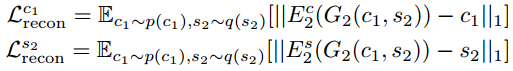 即,内容c和样式s的编码器对于生成后的图片也是适用的。
即,内容c和样式s的编码器对于生成后的图片也是适用的。
最后一个需要关注的loss是对抗loss,即,通过上述交叉domain生成的图片必须与内部本身domain生成的图片无法区分:
![]()
所以综合上面的3个loss考虑,我们需要的总的loss如下:
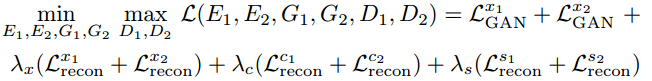
这些loss在MUNIT的tensorflow源码中也有对应(代码位置:https://github.com/taki0112/MUNIT-Tensorflow/blob/master/MUNIT.py):
Generator_A_loss = self.gan_w * G_ad_loss_a + \
self.recon_x_w * recon_A + \
self.recon_s_w * recon_style_A + \
self.recon_c_w * recon_content_A + \
self.recon_x_cyc_w * cyc_recon_A
Generator_B_loss = self.gan_w * G_ad_loss_b + \
self.recon_x_w * recon_B + \
self.recon_s_w * recon_style_B + \
self.recon_c_w * recon_content_B + \
self.recon_x_cyc_w * cyc_recon_B
其中self.recon_x_w等以_w结尾是各自的权重。
MUNIT的自编码器的实际实现架构如下:
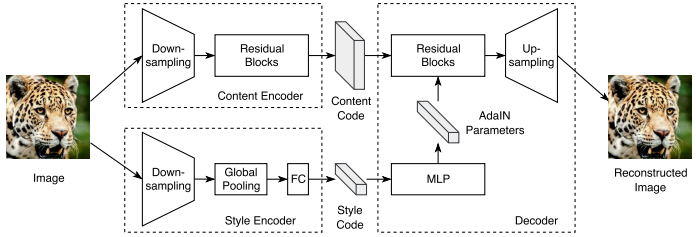
其中的内容编码器(content encoder)和样式编码器(style encoder)没什么好讲的。有意思的是解码器中要很好地整合c编码器和s编码器(内容和样式的完美合成),使用了自适应样例规范化Adaptive Instance Normalization (AdaIN) 技术,同时用一个MLP网络生成参数,辅助Residential Blocks生成高质量图片:
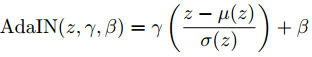
其中z代表前面的层输出的内容信息特征,u 和 σ 是对z的一些通道平均值和方差计算,γ 和 β 就是MLP从样式信息s生成的参数,用来调整图片生成(让图片内容更适应图片样式)。
对应代码在https://github.com/taki0112/MUNIT-Tensorflow/blob/master/ops.py :
def adaptive_instance_norm(content, gamma, beta, epsilon=1e-5):
# gamma, beta = style_mean, style_std from MLP
c_mean, c_var = tf.nn.moments(content, axes=[1, 2], keep_dims=True)
c_std = tf.sqrt(c_var + epsilon)
return gamma * ((content - c_mean) / c_std) + beta
看一下MUNIT与其他模型比较(清晰度和多样性):
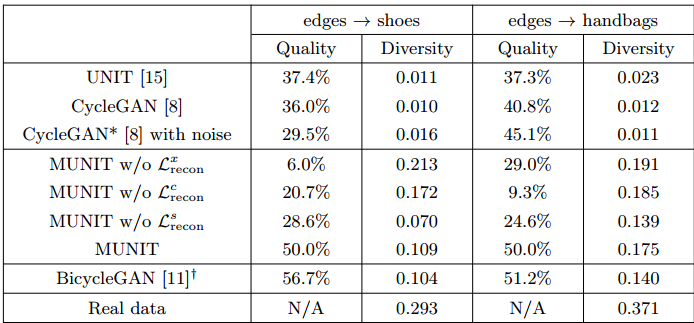
上表是从草图生成实际的鞋子和手袋的图片生成任务,可见MUNIT算是在无监督和多态之间找到了较好的平衡点。
最后看看MUNIT的图片生成样例:


参考文献:
- Multimodal Unsupervised Image-to-Image Translation
- https://github.com/taki0112/MUNIT-Tensorflow
- https://github.com/NVlabs/MUNIT
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
确定这篇论文是发在 CVPR 2018 上的吗?
可能是投稿但未收录:
https://arxiv.org/list/cs.CV/1804