
人类的想象力似乎是天生的, 而现今计算机的”想象力”来自”数据增强”技术. — David 9
这届CVPR上, 苹果为博得AI界眼球, 竟然拿到了最佳论文 ! 也许这篇论文没有什么深远意义,也许只能反映学术被业界商界渗透的厉害,也许有更好的文章应该拿到最佳论文。
这又何妨, 历史的齿轮从来不会倒退, David 9看到的趋势是, 人类越来越擅长赋予计算机”想象力”, 以GAN为辅助的”数据增强”技术是开始, 但绝不是终点 !
言归正传, 来剖析这篇论文, 首先,这篇文章的目标非常清晰,就是用非监督训练集,训练一个“图片优化器”(refiner),用来优化人工模拟图片,使得这一模拟图片更像真实图片,并且具有真实图片的独特属性:
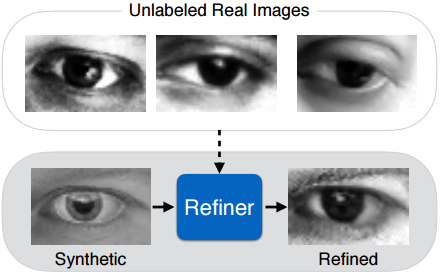
如上图,人工模拟的伪造图片(Synthetic)经过优化器Refiner变得与非监督集合(第一行的3张图片)非常相似,极大的增强了模拟图片的真实性。
了解GAN的朋友一定看出来了, 这里的Refiner只是GAN中生成器另一种叫法而已,我们这就把判别器(Discriminator)加上:
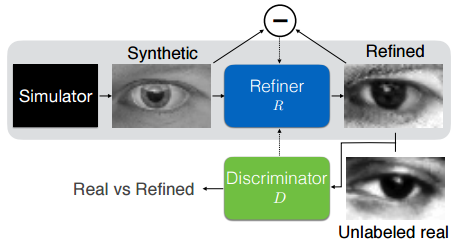
这样,整个对抗学习更加清晰了。对于Refiner(本质上是个生成器)的 损失函数如下:
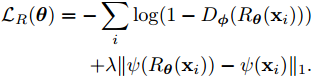 这里的D是判别器,R是图片优化器。Φ和θ是各自模型带的所有参数。前一半式子告诉模型R尽力欺骗判别函数D, 使得D认为R的输出就是真实样本。
这里的D是判别器,R是图片优化器。Φ和θ是各自模型带的所有参数。前一半式子告诉模型R尽力欺骗判别函数D, 使得D认为R的输出就是真实样本。
ψ是从图片空间到特征空间的映射。后一半式子做了一个正则化,使得每张优化过后的图片和原来那一张图片不会相差太远。
对于判别器D,损失函数是这样的:
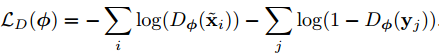
即最大限度地通过D区分出优化模拟后的样本和真实样本.
整个算法如下:

整个对抗学习中每次迭代, 先更新图片优化器R的损失函数, 再更新判别器D的损失函数.(奇怪为什么不先预训练一下判别器D?)
这里判别器D用了两个Trick.
1. GAN中判别器一般比生成器更”强”一些. 但是太强也会出现问题,如果判别器只关注整体特征,而总是用全局特征去区分样本是“真实”或是“伪造”,这就会出现偏移和偏差的问题。于是,文章用全卷积去做局部块的损失评估: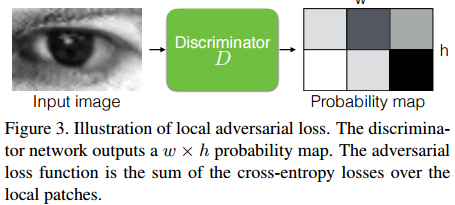
2. 另外,为了使得每次对模拟图片优化出来的图片具有差异性(总是生成相似的图片),训练时,随机地在判别器D的mini-batch中加入之前历史刚生成的一些图片作为“伪造”图片的输入:
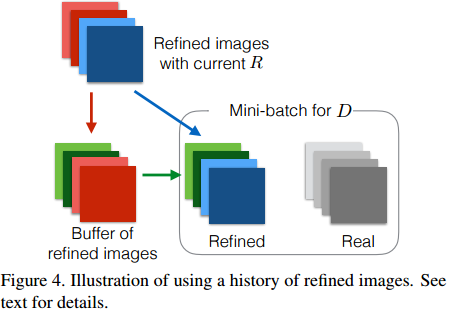
接下来欣赏一组实验图片:


当然,整篇论文的图片优化器,不是为了优化得像真实图片而优化。而是,回到我们的开篇主旨: 数据增强 !
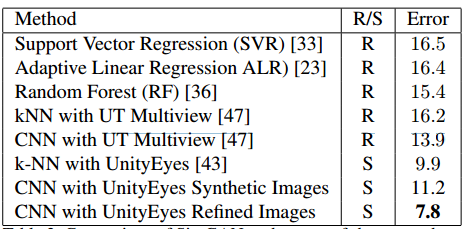 上图是各种state-of-the-art框架在MPIIGaze数据集上的分类效果,第二列代表是用真实数据(R)还是用数据增强过的数据(S)去做的训练。明显看到用论文中的方法,数据增强(优化)后的训练错误率低达7.8%。不错哟。
上图是各种state-of-the-art框架在MPIIGaze数据集上的分类效果,第二列代表是用真实数据(R)还是用数据增强过的数据(S)去做的训练。明显看到用论文中的方法,数据增强(优化)后的训练错误率低达7.8%。不错哟。
是不是感受到了计算机的”想象力”——”数据增强”的一丝丝威力?源码地址可在参考文献中找到。
参考文献:
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024