如果不存在至高的上帝,那么也不存在至高的解释,不论解释者做何种努力 — David 9
假想这样一个场景,世界上仅有两个至高的神(比如“宙斯”和“赫拉”),互相解释同一件事情。虽然宙斯和赫拉都是无所不知的神,但我们假设宙斯对赫拉并不是无所不知的(同样赫拉对宙斯也是):
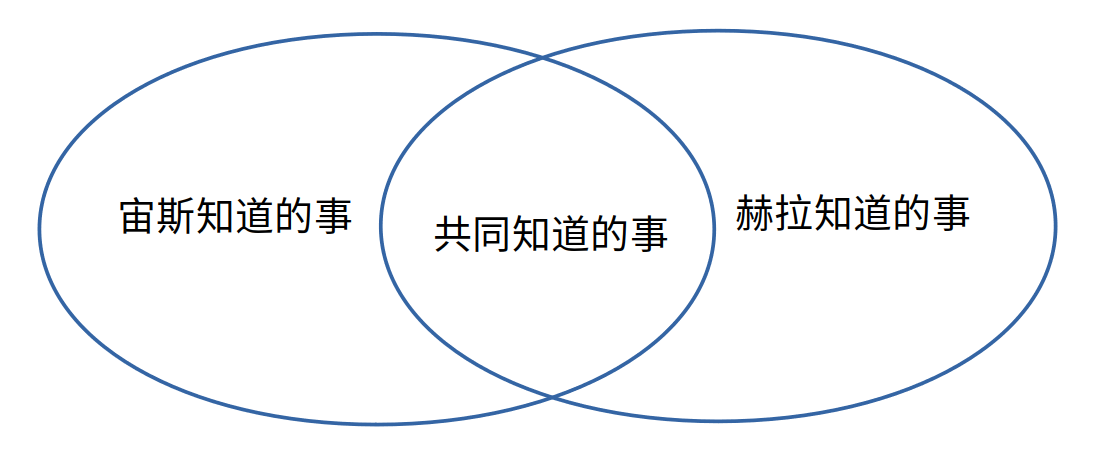
那么,他们相互可以解释清楚同一件事情吗?
因为赫拉除了宙斯之外已经无所不知了,那么,宙斯向赫拉解释的过程就退化为:把自己对这件事所知道的信息传递给赫拉。
如果宙斯需要解释的信息都是共同知道的信息,那这种信息传递较容易。但如果解释中包括了宙斯知道的信息而赫拉不知道的,那么赫拉将难以理解和消化。并且,宙斯不知道赫拉有哪些事是已经知道的,所以宙斯不一定能高效地把自己知道的一切让赫拉明白。
也许,最高效的解释不仅是找到共同可以理解的交集,也在于如何预测对方可能已经知道的信息。
回到正题,对于复杂模型的解释,人们普遍停留在找“可以共同理解”的交集,当然, 继续阅读复杂模型解释的几种方法(interpret model): 可解释,自解释,以及交互式AI的未来#2,第二弹
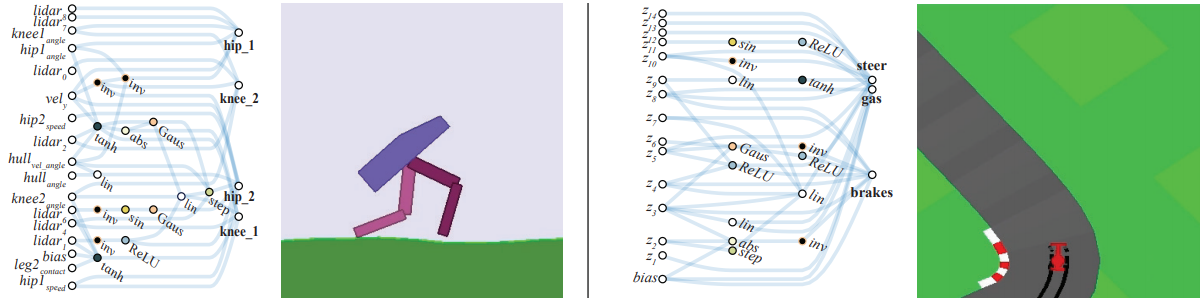

 ),它用各种“更高明的”(包含人类先验的)方式利用大量无标签的样本,自我强化和丰富已有的有标签样本模型。
),它用各种“更高明的”(包含人类先验的)方式利用大量无标签的样本,自我强化和丰富已有的有标签样本模型。