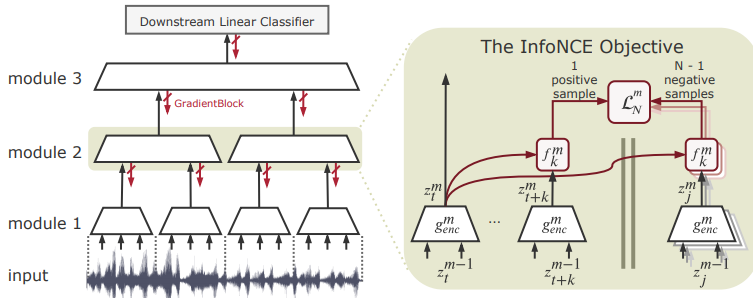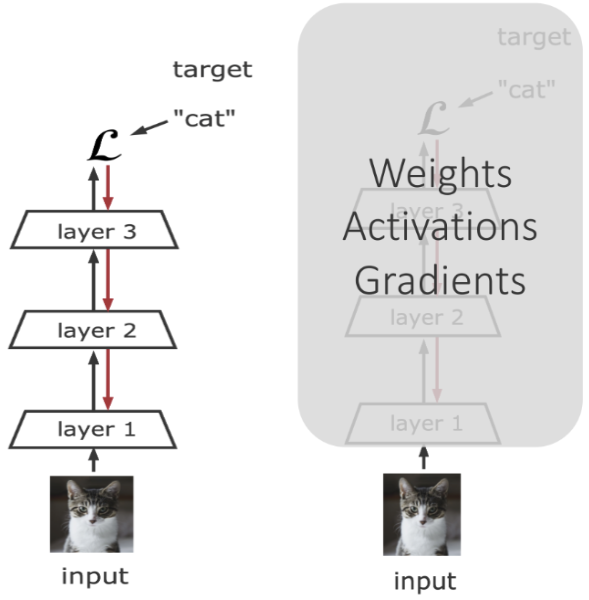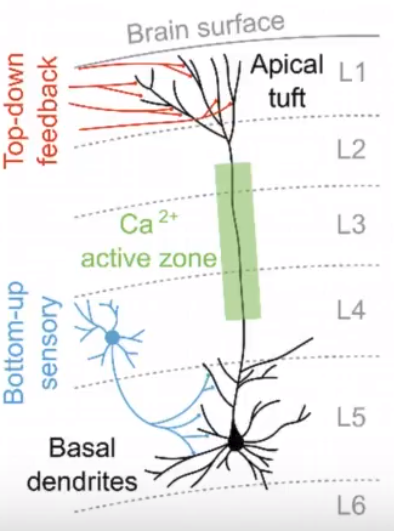
正确的废话总是令人讨厌,如果,正确的废话再具体一点?或选个好角度再具体一点呢?—— David 9
科学界有这样一些论文题目,看起来有点意思,请允许David列出一些:
- “Transformers are Graph Neural Networks”
- “Deep Neural Networks as Gaussian Processes”
- “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”
- “Wide Feedforward or Recurrent Neural Networks of Any Architecture are Gaussian Processes”
一些研究人员大胆地指出:A其实就是B!这就像告诉我们,“天上的云其实就是水分子,光其实也是一种波,妈妈唠叨其实是为了关心你”。看起来似乎都是正确的废话。 但是有两点值得注意:
但是有两点值得注意:
1. 这至少可以帮你换个角度解释世界。
2. A其实就是B,是说A被B包含,即A⊆B,说明,B的解释范围比A大(得多), 继续阅读为什么说Transformer模型甚至神经网络的“颠覆”会更早到来?以及神经网络的“表达力”并非真正的“壁垒”?