所谓无监督学习,只是人类加入了约束和先验逻辑的无监督 — David 9
更新:有同学发现这篇文章可能并没有在CVPR2018最终录取名单(只是投稿),最终录取名单参考可以看下面链接:
https://github.com/amusi/daily-paper-computer-vision/blob/master/2018/cvpr2018-paper-list.csv
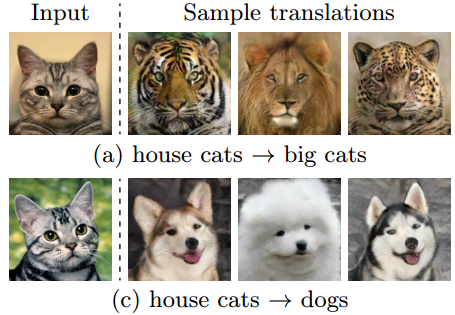
最近图片生成领域正刮着一股“无监督”之风,David 9今天讲Cornell大学与英伟达的新作,正是使无监督可以生成“多态”图片的技术,论文名:Multimodal Unsupervised Image-to-Image Translation (MUNIT)。
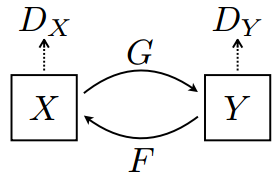
这股“无监督”之风的刮起,只是因为我们发现用GAN结合一些人为约束和先验逻辑,训练时无需监督图片配对,直接在domain1和domain2中随机抽一些图片训练,即可得到样式转换模型。这些约束和先验有许多做法,可以迫使样式转换模型(从domain1到domain2)保留domain1的一些语义特征;也可以像CycleGAN的循环一致约束,如果一张图片x从domain1转换到domain2变为y,那么把y再从domain2转换回domain1变为x2时,x应该和x2非常相似和一致:
而这些无监督方法有一个缺陷:不能生成多样(多态)的图片。MUNIT正是为了解决这一问题提出的,因为目前类似BicycleGAN的多态图片生成方法都需要配对监督学习。
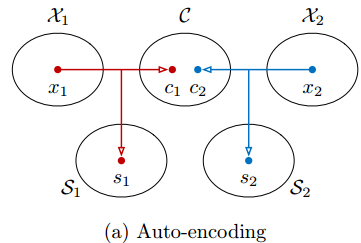
MUNIT为此做了一些约束和假设,如,假设图片有两部分信息:内容c和样式s,另外,图片样式转换时domain1和domain2是共享内容c的信息空间的:
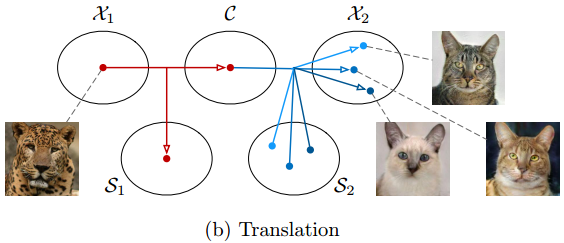
生成图片时,把同一个内容c和不同样式s组合并编码输出,就可生成多态的图片:
实际训练时,我们需要两个自编码器,分别对应domain1和domain2: 继续阅读CVPR2018精选#1: 无监督且多态的图片样式转换技术,康奈尔大学与英伟达新作MUNIT及其源码