
命名实体识别 (NER) 是语义理解中的一个重要课题。NER就像自然语言领域的“目标检测”。找到文档D 中的名词实体还不够,许多情况下,我们需要了解这个名词是表示地点(location),人名(Person)还是组织(Organization),等等:

上图是NER输出一个句子后标记名词的示例。
在神经网络出现之前,几乎所有NER半监督或者非监督的方法,都要依靠手工的单词特征或者外部的监督库(如gazetteer)达到最好的识别效果。
手工的单词特征可以方便提炼出类似前缀,后缀,词根,如:
-ance, —ancy 表示:行为,性质,状态/ distance距离,currency流通
-ant,ent 表示:人,…的/ assistant助手,excellent优秀的
–ary 表示:地点,人,事物/ library图书馆,military军事
可以知道-ant结尾的单词很可能是指人,而-ary结尾更可能指的地点。
而外部的监督库(如gazetteer),把一些同种类的实体聚合在一起做成一个库,可以帮助识别同一个意思的实体,如:
auntie其实和aunt一个意思:姨妈
Mikey其实是Mike的昵称,都是人名
今天所讲的这篇卡内基梅隆大学的论文,用RNN神经网络的相关技术避开使用这些人工特征,并能达到与之相当的准确率。
为了获取上述的前缀,后缀,词根等相关特征,文章对每个单词的每个字母训练一个双向LSTM,把双向LSTM的输出作为单词的特殊embedding,和预训练eStack LSTM的算法识别命名实体,感兴趣可以继续阅读原论文。mbedding合成最后的词嵌入(final embedding):
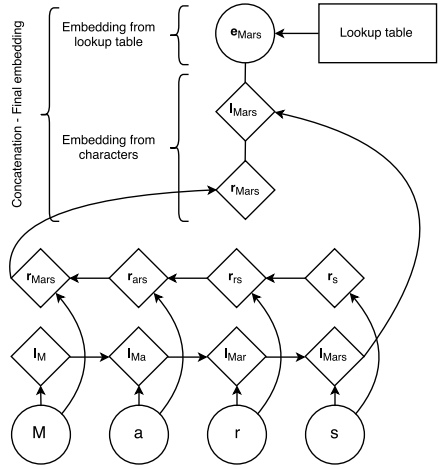
双向LSTM可以捕捉字母拼写的一些规律(前缀,后缀,词根), 预训练的embedding可以捕捉全局上单词间的相似度。两者结合我们得到了更好的词嵌入(embedding)。
有词嵌入表征是远远不够的,我们要有效利用这些embedding处理NER问题,一个NER预测问题和一般的机器学习差别不大:给出一个训练集(已经标注过命名实体的文档集),用测试集(未标注命名实体的文档)上的NER识别率来评价模型。
论文中为了提高上述的命名实体识别率,结合了两方面评估:
1. 对于词性tag的下一个单词可能词性tag的建模(如“吃”这个动词后大概率是类似“食物”(“饭”,“面条”等)的实体,“吃”后面极少跟“地点”的实体)
2. 对于一个单词(抛去词性),同时结合上下文单词,这个单词最可能的命名实体。
上述的第2点可以用双向LSTM建模(输入是我们之前提到的单词embedding),第1点可以用条件随机场(CRF)建模(与马尔科夫链相似)。两点结合后的模型架构如下:
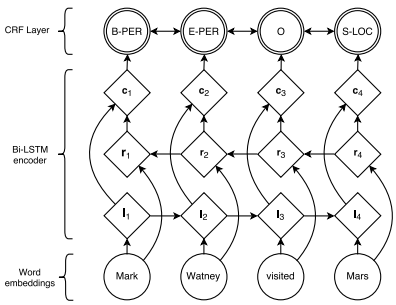
其中最底层的(word embedding)就是我们前面提到的单词embedding。
中间层(Bi-LSTM)l 代表单词左侧的上下文特征, r 代表单词右侧的上下文特征,c 代表了左右两侧的合成。
最高层(CRF)把单词tag之间的关系建模,提高NER准确率。
落实到损失函数,文中也用了上述两方面的因素(tag到tag的转移率,单词是某个tag的概率):
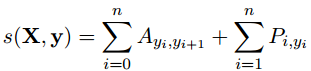
其中,X=(x1, x2, . . . , xn) , 代表一个序列的句子 ,
y = (y1, y2, . . . , yn), 代表对上述序列的tag预测
s(X,y)即对本次预测的打分(score)
第一部分矩阵 Ayi,yi+1 代表tag yi 转移到后一个tag yi+1的可能性的打分
第二部分矩阵 Pi,yi 是第i个单词预测为tag yi 的可能性。
最后看一下实验数据:
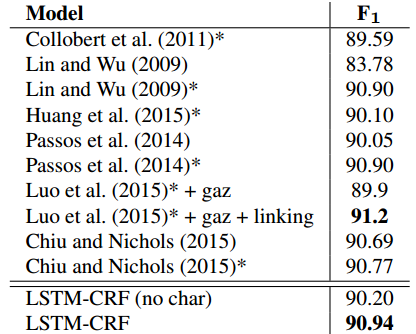
如预想的,LSTM-CRF如果没有使用单字符的embedding提取,结果会稍逊色一些。
另外,出来LSTM-CRF,文章还使用了层叠Stack LSTM的算法识别命名实体,感兴趣可以继续阅读原论文。
参考文献:
- Neural Architectures for Named Entity Recognition
- http://eli5.readthedocs.io/en/latest/tutorials/sklearn_crfsuite.html
- https://github.com/glample/tagger
- https://github.com/clab/stack-lstm-ner
- http://www.datacommunitydc.org/blog/2013/04/a-survey-of-stochastic-and-gazetteer-based-approaches-for-named-entity-recognition-part-2
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024