上一期的Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门 #第二讲 中, 谈到过word2vec, 但是究竟什么是Word2vec ? 以及skip-Gram模型和CBOW模型究竟是什么? 也许还有小伙伴不是很明白, 这一次我们来好好讲一下这两种word2vec:
- 连续Bag-of-Words (COBW)
- 从上下文来预测一个文字
- Skip-Gram
- 从一个文字来预测上下文
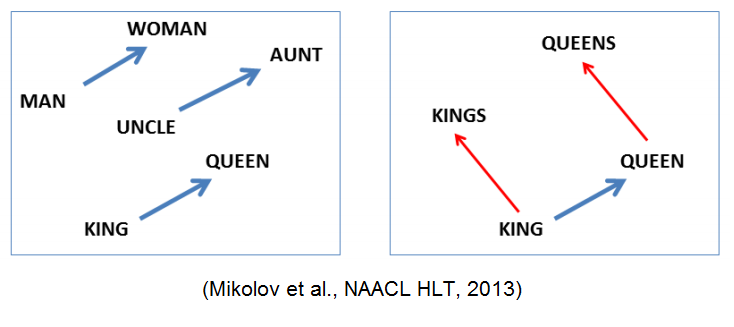
其实, 用一个向量唯一标识一个word已经提出有一段时间了. Tomáš Mikolov 的word2vec算法的一个不同之处在于, 他把一个word映射到高维(50到300维), 并且在这个维度上有了很多有意思的语言学特性, 比如单词”Rome”的表达vec(‘Rome’), 可以是vec(‘Paris’) – vec(‘France’) + vec(‘Italy’)的计算结果.
接下来, 上word2vec示意图:
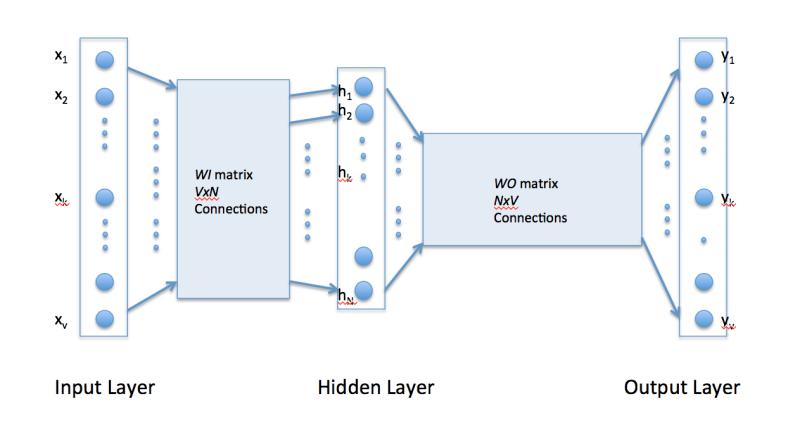
很显然, word2vec是只有一个隐层的全连接神经网络, 用来预测给定单词的关联度大的单词.
WI 的大小是VxN, V是单词字典的大小, 每次输入是一个单词, N是你设定的隐层大小.
举个例子, 如果我们的语料仅仅有这3句话: “the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree”. 那么单词字典只有8个单词: “the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”.
那么V=8, 输入层的初始就可以是:
[0, 0, 0, 0, 0, 0, 0, 0] 代表: [“the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”]
输入[“”, “dog“, “”, “”, “”, “”, “”, “”] 可以表示为: [0, 1, 0, 0, 0, 0, 0, 0]
输入[“”, “”, “saw“, “” , “”, “”, “”, “”] 可以表示为: [0, 0, 1, 0, 0, 0, 0,0]
如果是在字典中有的, 就用1表示
W0 的大小是NxV, 于是, 通过训练完毕的WI 和W0 , 只要输入单词, 就能预测出最符合这个上下文的下一个单词. 当然这个单词一定是字典中有的, 就是说在大小V中的字典中, 选出概率最大的那个单词.
那么, 连续Bag-of-Words (COBW)又是怎么从上下文来预测一个文字呢 ? 其实它就是通过拷贝上面word2vec的输入层做到的:
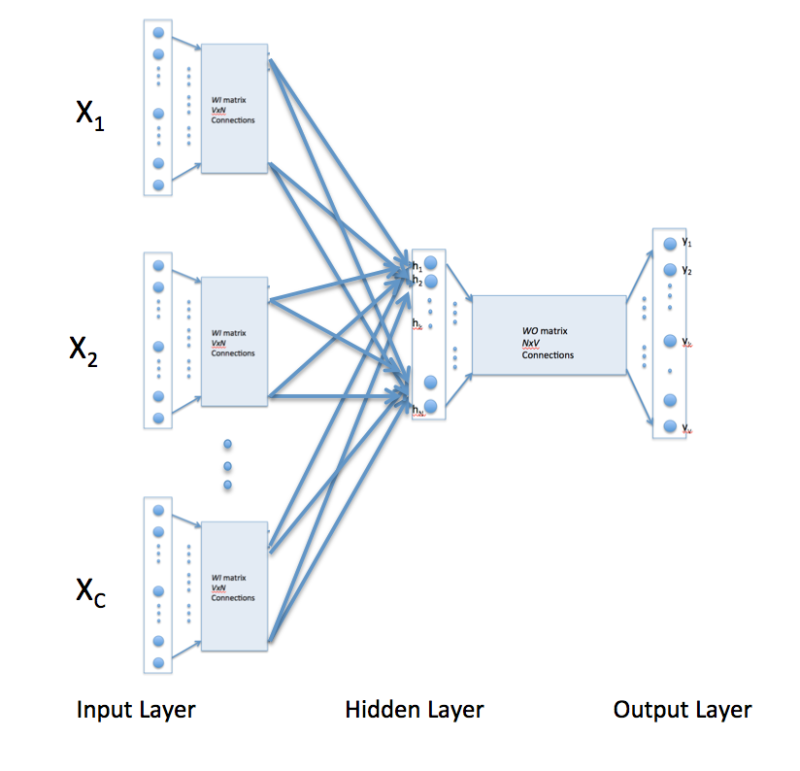
这样, 拷贝次数C就是这个短语的长度, 即单词个数. 输入层和隐含层之间就多了好多个W矩阵, 每个矩阵就代表了这个单词对隐层的影响和贡献. 最后的NxV矩阵依然能预测出最可能的下一个单词.
Skip-Gram就是把上图颠倒过来, 如果你要预测的输出上下文的单词个数是C, 那么, 就像CBOW一样, 拷贝C次输入矩阵就OK啦.
参考文献:
https://iksinc.wordpress.com/tag/skip-gram-model/
David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024