当深度网络应用在增强学习中,人们发现一些训练的捷径,但是没有统一的看法。每当深度网络应用在一个领域,总是会重复类似的故事,这也许正是深度学习有意思的地方 — David 9
如果你想入深度增强学习的坑,你一定发现在增强学习domain下,深度网络构建有那么多技巧。
不像一般的机器视觉,深度网络在增强学习中被用来理解环境(states)和回报值(reward),最终输出一个行为策略。
因此关注的最小粒度其实是行为(action),依旧使用传统梯度下降更新网络并不高效(行为的跳跃很大,梯度更新可能很小)。另外,增强学习其实是可以高并行的问题,试想如果你有很多分身去玩Dota,最后让他们把关键经验告诉你,就省去了很多功夫。
在经验和行为主导的增强学习背景下,催生了DQN,A3C,Evolution Strategies等一系列深度网络的训练方法。包括我们今天的主角:遗传算法(GA)。
Uber AI实验室发现GA对行为策略的把控,可以结合到深度网络中,他们称之为深度神经进化(Deep Neuroevolution),在某些领域的表现甚至超过了DQN,A3C,Evolution Strategies。
遗传算法(GA)是一个模拟种族(polulation)遗传进化的算法,一开始假设种族人口上限是N,经过一代一代的基因遗传与变异,最后那一代种族对自然环境的适应力是最高的(当然其中有最适应环境的一些个体,也有不适应的一些个体但是环境变化他们也许有优势)。
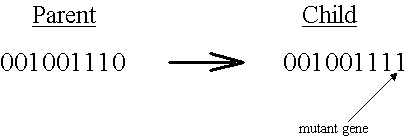
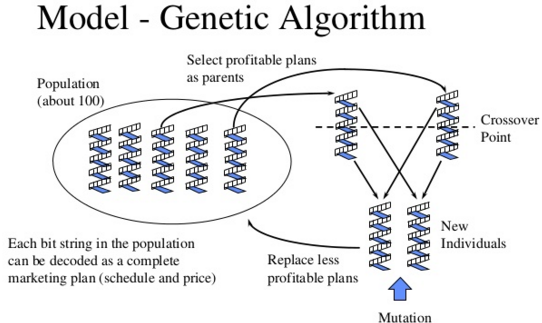
所以遗传算法(GA)是怎么用在深度网络中的呢?事实上,一个策略(解决方案)可以看做一个种群个体:
 对于遗传变异,文章结合了novelty search,为了避免局部最优解,给予不常见的行为更大回报值。即,鼓励族群生成差异化比较大的个体(策略)。
对于遗传变异,文章结合了novelty search,为了避免局部最优解,给予不常见的行为更大回报值。即,鼓励族群生成差异化比较大的个体(策略)。
源码已经被Uber开源了,感兴趣可以深入研究:
https://github.com/uber-common/deep-neuroevolution
实验方面,Atari是20世纪80年代街机鼻祖,文章的实验以Atari的许多款游戏为环境:
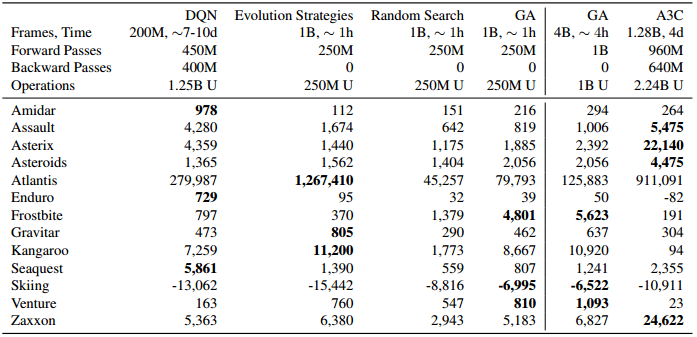
纵列是每种算法在各个游戏环境中的分数(分数越高越好),可见遗传算法(GA)性能远超随机搜索,但并不是在所有环境下都比其他算法好。另外文章也提到,GA平均计算速度甚至比Evolution Strategie还快(也许因为遗传算法很适合高并行)。
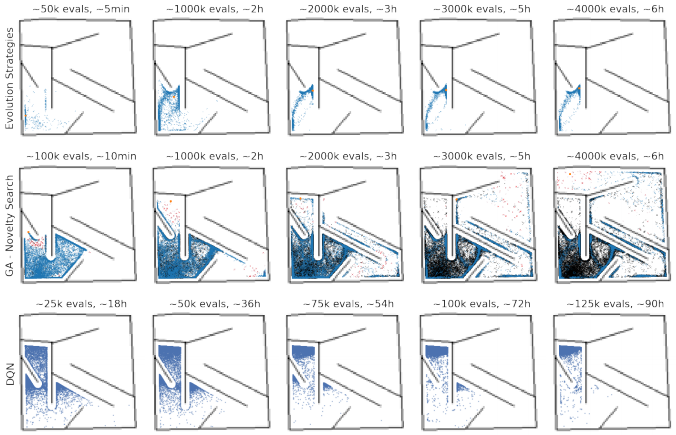
下图展示了用novelty search进行GA搜索可以一定程度跳出局部最优:
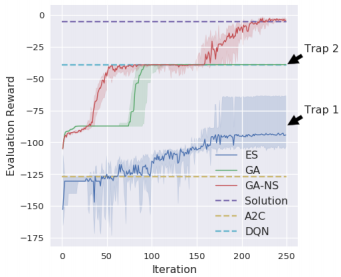
并且在搜索迷宫的过程中,GA-NS展现了更完整的空间搜索,其中点出现的地方是算法探索的位置,显然ES相较GA-NS有太多点的重叠,缺少探索性:
参考文献:
- Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
- https://github.com/uber-common/deep-neuroevolution
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
但是启发式搜索算法在深度学习中的应用,时效性的分析是一个问题,效果的收敛保证也是一个问题啊
是的,收敛性是一个很有意思的问题。
我还没仔细看论文的收敛性证明,但是猜测文章是在已有的优化策略上结合GA,而不是完全抛弃已有的优化算法。
如果你有深入理解文章的收敛性,也请分享出来,供大家参考。