GAN凝结了人们对”创作”本质的看法 — David 9
虽然ICLR 2018 要明年5月举办, 一些企业巨头已经摩拳擦掌,前不久,英伟达正在审阅的论文引起了大家注意,David 9觉得很有意思。论文用深度增长的网络构建、并生成稳定,高质量,多样的GAN对抗样本图片 :

上图demo是深度增长网络GAN生成的明星样本,清晰度和质量堪称惊艳。论文打破了神经网络在训练过程中“架构不变”的惯性思维。为了更好地“临摹”高清的明星脸谱,训练过程中,先从“粗略模糊”地“勾勒”开始对抗学习:
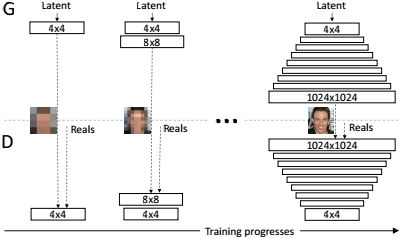
如图,先从清晰度较低的4*4像素图片开始训练GAN(这时判别器D和生成器G都只有一层cnn),逐步地,提高卷积层数(这时生成的图片清晰度也自然地提高)。。直到训练的最后阶段,网络的深度已经可以支持生成1024*1024的图片了。
训练这样深度增长网络的初衷,就是要充分利用之前训练的模糊图片的生成能力,有了这种粗略的描绘能力,使得逐渐生成高清的图片变得简单。
要知道,如果一开始就用非常深的判别器D和生成器G去生成1024*1024的高清图片,一方面D的判别太简单了(因为高清图片的判别太简单了),同时G的更新也显得随机而盲目。
因此,为了平滑地构建深度增长网络,整个过程中使用类似残差网络拼接特征图的方式:
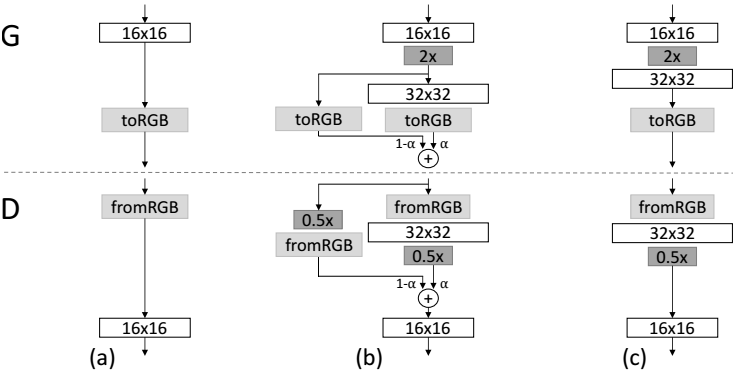
以增加一层32*32输出的层为例,在增加之前,我们看到图(a),只有16*16的较模糊的输出层。
增加时,对于生成器G,我们用图中2x操作(类似拉伸图片的filter)把16*16的图片拉伸到32*32,再和32*32层的输出合并(这里主要合并时是有权重α的并不是相等权重的合并),直觉上,应该让32*32的输出有更大的权重(毕竟本来的16*16输出只是一个模糊的“临摹”)。
而对于判别器,我们使用相反的操作,把32*32的清晰图通过模糊化的filter模糊化到 16*16的输出即可。随着逐步地加深卷积层,最后即可生成非常清晰的图片:

文章用Sliced Wasserstein distance (SWD)评估模型的生成样本质量,即生成图片和原始训练图片的相似度评估:
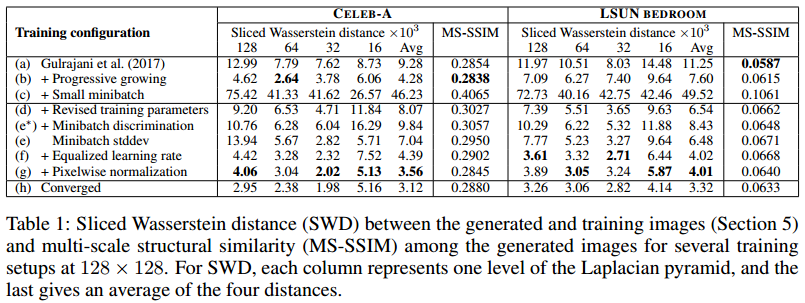

(a)-(g)列的图片对应各种模型的生成样本,也对应上图表格中的行(a)-(g)的结果。
参考文献:
- PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
- https://github.com/tkarras/progressive_growing_of_gans
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024