CVPR 2017在即,David 9最近补习了目标检测的趋势研究。深度学习无疑在近年来使机器视觉和目标检测上了一个新台阶。初识目标检测领域,当然先要了解下面这些框架:
- RCNN
- Fast RCNN
- Faster RCNN
- Yolo
- SSD
附一张发表RCNN并开启目标检测深度学习浪潮的Ross B. Girshick(rbg)男神:
 无论如何,目标检测属于应用范畴,有些机器学习基础上手还是很快的,所以让我们马上来补习一下!
无论如何,目标检测属于应用范畴,有些机器学习基础上手还是很快的,所以让我们马上来补习一下!
首先什么是目标检测?目标检测对人类是如此简单:
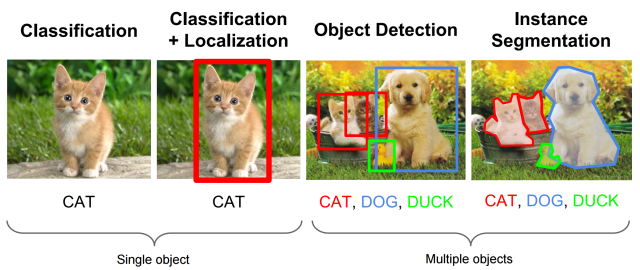
把存在的目标从图片中找出来,就是那么简单!
在计算机中,传统目标检测方法大致分为如下三步:

如上图所示,首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。下面我们对这三个阶段分别进行介绍。
(1) 区域选择
这一步是为了对目标的位置进行定位。由于目标可能出现在图像的任何位置,而且目标的大小、长宽比例也不确定,所以最初采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺度,不同的长宽比。这种穷举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:时间复杂度太高,产生冗余窗口太多,这也严重影响后续特征提取和分类的速度和性能。(实际上由于受到时间复杂度的问题,滑动窗口的长宽比一般都是固定的设置几个,所以对于长宽比浮动较大的多类别目标检测,即便是滑动窗口遍历也不能得到很好的区域)
(2) 特征提取
由于目标的形态多样性,光照变化多样性,背景多样性等因素使得设计一个鲁棒的特征并不是那么容易。然而提取特征的好坏直接影响到分类的准确性。(这个阶段常用的特征有SIFT、HOG等)
(3) 分类器
主要有SVM, Adaboost等。
总结:传统目标检测存在的两个主要问题:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。
深度学习特别是CNN的出现使得上述第2,3步可以合并在一起做:
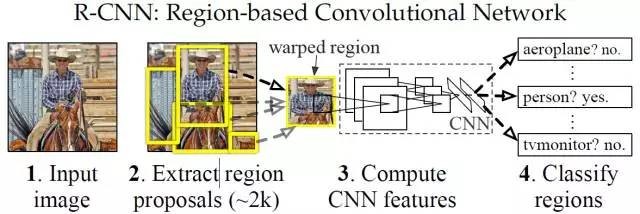
R-CNN (CVPR2014, TPAMI2015)
上图就是有名的R-CNN (Region-based Convolution Networks for Accurate Object detection and Segmentation)。
训练流程:
(1) 输入测试图像
(2) 利用selective search算法在图像中提取2000个左右的region proposal(候选区)。
(3) 将每个region proposal缩放(warp)成227×227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
(4) 将每个region proposal提取到的CNN特征输入到SVM进行分类。
针对上面的框架给出几点解释:
* 上面的框架图是测试的流程图,要进行测试我们首先要训练好提取特征的CNN模型,以及用于分类的SVM:使用在ImageNet上预训练的模型(AlexNet/VGG16)进行微调得到用于特征提取的CNN模型,然后利用CNN模型对训练集提特征训练SVM。
* 对每个region proposal缩放到同一尺度是因为CNN全连接层输入需要保证维度固定。
* 上图少画了一个过程——对于SVM分好类的region proposal做边框回归(bounding-box regression),边框回归是对region proposal进行纠正的线性回归算法,为了让region proposal提取到的窗口跟目标真实窗口更吻合。因为region proposal提取到的窗口不可能跟人手工标记那么准,如果region proposal跟目标位置偏移较大,即便是分类正确了,但是由于IoU(region proposal与Ground Truth的窗口的交集比并集的比值)低于0.5,那么相当于目标还是没有检测到。
小结:R-CNN在PASCAL VOC2007上的检测结果从DPM HSC的34.3%直接提升到了66%(mAP)。如此大的提升使我们看到了region proposal+CNN的巨大优势。
但是R-CNN框架也存在着很多问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
Fast R-CNN(ICCV2015)
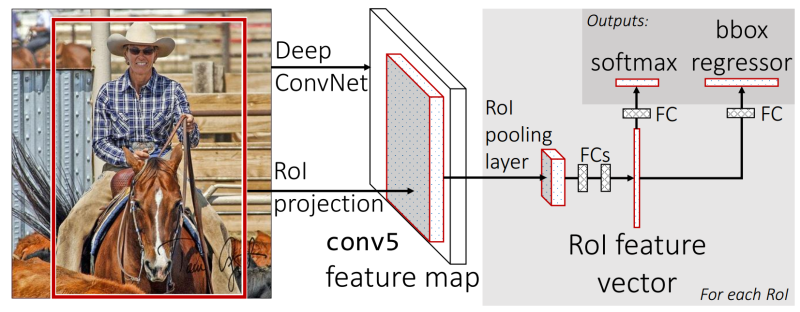
Fast R-CNN较R-CNN有两点重要改进:
1. 最后一个卷积层后加了一个ROI pooling (Region of Interes pooling) layer。
2. 损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。
这两个改进使得CNN在应用时更浑然一体,节省时间开销。
如果你的输入图片如下:

那么区域候选可能如下:

最后一层卷积输出的所有通道就可能如下:
 Fast R-CNN中,我们会对每个输出通道做ROI pooling,比如对于如上小绿框做pooling:
Fast R-CNN中,我们会对每个输出通道做ROI pooling,比如对于如上小绿框做pooling: 就会有一下两个输出:
就会有一下两个输出:

Fast R-CNN使得最后一层卷积后的网络得到了很大的优化,但是很大的缺陷是它依然依赖region proposal给出的结果, 而计算region proposal本身会消耗很多时间。
Faster R-CNN(NIPS2015)
(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
对于Region Proposal的劣势,Faster R-CNN给出了改进,如果找到一种方法只提取几百个或者更少的高质量的预选窗口,而且召回率很高,这不但能加快目标检测速度,还能提高目标检测的性能(假阳例少)。RPN(Region Proposal Networks)网络应运而生。
RPN的核心思想是使用卷积神经网络直接产生region proposal:
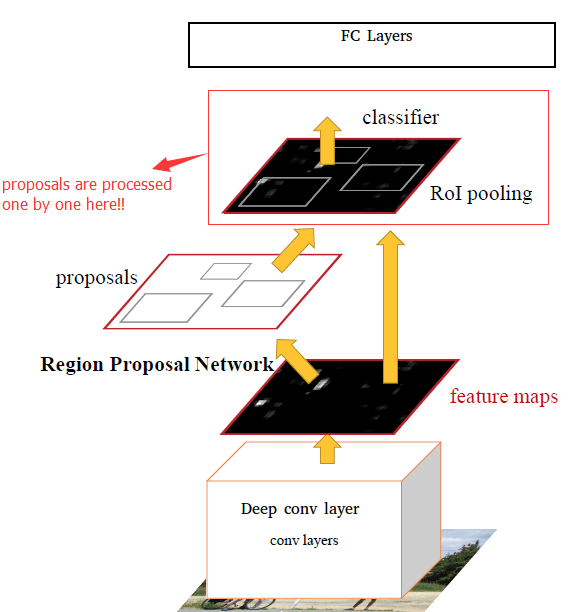
使用的方法本质上就是滑动窗口。RPN的设计比较巧妙,RPN只需在最后的卷积层上滑动一遍,因为anchor机制和边框回归可以得到多尺度多长宽比的region proposal:
 3*3滑窗对应的每个特征区域同时预测输入图像3种尺度(128,256,512),3种长宽比(1:1,1:2,2:1)的region proposal,这种映射的机制称为anchor:
3*3滑窗对应的每个特征区域同时预测输入图像3种尺度(128,256,512),3种长宽比(1:1,1:2,2:1)的region proposal,这种映射的机制称为anchor: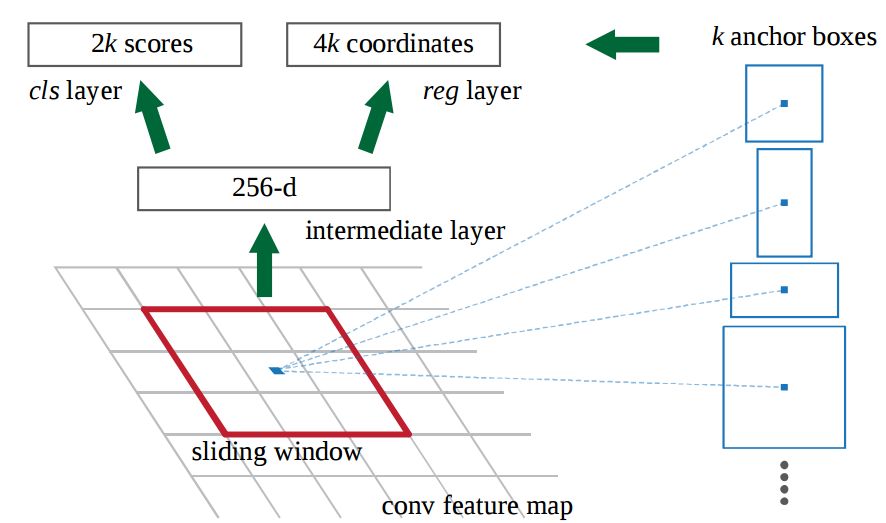
总的来说,从R-CNN, Fast R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于region proposal的R-CNN系列目标检测方法是当前目标最主要的一个分支。
然而,对于实时训练,R-CNN系列依然不能做到,而YOLO这类目标检测方法的出现让实时性也变的成为可能。且待David 9下回分解。
参考文献:
- http://note.youdao.com/share/?id=92ca896a56afdc7cc18a097b2b428323&type=note#/
- http://blog.csdn.net/he_is_all/article/details/56485921
- https://arxiv.org/pdf/1611.10012.pdf
- https://www.zhihu.com/question/35887527
- https://www.koen.me/research/selectivesearch/
- https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/object_localization_and_detection.html
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

The following two tabs change content below.




David 9
邮箱:yanchao727@gmail.com
微信: david9ml
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
《机器视觉目标检测补习贴之R-CNN系列 — R-CNN, Fast R-CNN, Faster R-CNN》上有1条评论